
The AI Music That "Actually" Listens Audience
An introduction, of sorts.

By day, I write software somewhere in California. By night — or whatever fragments of night a job and two kids leave behind — I make techno on modular synthesizers. I’m not going to pretend I’m a virtuoso. I’m somewhere between beginner and intermediate, honestly. But I carry a memory from Ibiza in 2013 like a coal that never quite goes out, and the dream attached to it has never changed: I want to be an EDM artist.
I came to music late, and quietly. For years it was just me and a piano, playing new age pieces, soft things, music for empty rooms. But somewhere underneath all that quiet was a very different desire — I wanted to make music that makes people move. I’d sketch with virtual instruments in Logic, chasing textures, programming beats, always with this stubborn belief that if I could just find the right sound, the right groove, something great would come out of it.
Reality, of course, doesn’t care much about belief. You can own every plugin, every DAW, every beautiful piece of gear — and music will still demand everything from you. Time. Focus. Obsession. Things that are in short supply when you’re raising kids and holding down a full-time job. So music became what it becomes for so many of us: a hobby you touch once in a while, guiltily, like an old letter.
But the hunger never left. I’d listen to Adam Beyer, Armin van Buuren, deadmau5 — and every time, the same ache: I want to make this. I want to make this now.
Down the modular rabbit hole
About two years ago, deadmau5’s Masterclass introduced me to modular synthesis, and I fell hard. The sheer open-endedness of it — patch cables as sentences, voltage as intention — I was gone.
I bought a Moog Mother-32. Then practiced on soft modulars like Arturia’s Modular V. Then a DFAM, a Subharmonicon — I had the little Moog trio going, three boxes muttering to each other on my desk.
And then came the humbling. Hardware is expensive, yes. But the deeper lesson was this: if you don’t understand the depth of what electronic music actually is — how it’s constructed, why it works — no amount of gear will ever make good music for you. The machines don’t carry you. You carry them.
So I went back to school, in the self-taught sense. I found VCV Rack, that beautiful free universe. I studied Omri Cohen’s videos, read Patch & Tweak, dug into the fundamentals. And weirdly, learning how synthesizers actually work — oscillators, filters, envelopes, the whole anatomy — became one of the great joys of my life. Understanding, it turns out, is its own kind of high.
But understanding without performing is a library nobody visits. I wanted to play. And again, the same wall: full-time work, small children, no long stretches of deep time. The dream kept idling.
Then the machines started coding
In early-to-mid 2025, the AI coding wave hit. Claude Code, specifically, changed something in my head. Watching it work, I realized: I could actually build the world I’d been imagining.
Here’s the world. I don’t want AI that generates music. I want AI that understands electronic music — and expresses that understanding through modular synthesis.
You’ve seen the Suno-style generators. Type a prompt, receive a song. I don’t believe that’s real musical understanding. I don’t know their internals, but roughly speaking: if a model learns from waveforms and metadata and spits out audio, has it actually understood music? Or has it just learned what music statistically looks like from the outside?
I wanted something that understands music from the inside — the way a patch understands itself.
So starting in late 2025, between diaper changes and deploy schedules, I did what people now call “vibe coding.” Prompts, iterations, a lot of failure. Eight months later, I had the model I wanted. Technically, it’s a fine-tune of the recently released Gemma 4 — and because Gemma 4 ships under the Apache license, I could work in peace. I have no plans to sell any of this, but after a dozen-plus years as a software developer, I’m constitutionally incapable of being casual about licenses.
What I built is a model that understands modular synthesis through text. I call the model LSM, short for Large Synthesizer Model. It runs inside a broader system I’m building called DeepSynth, and I’m also building a Rust-based patching environment called PatchBee so I can actually perform with it live.
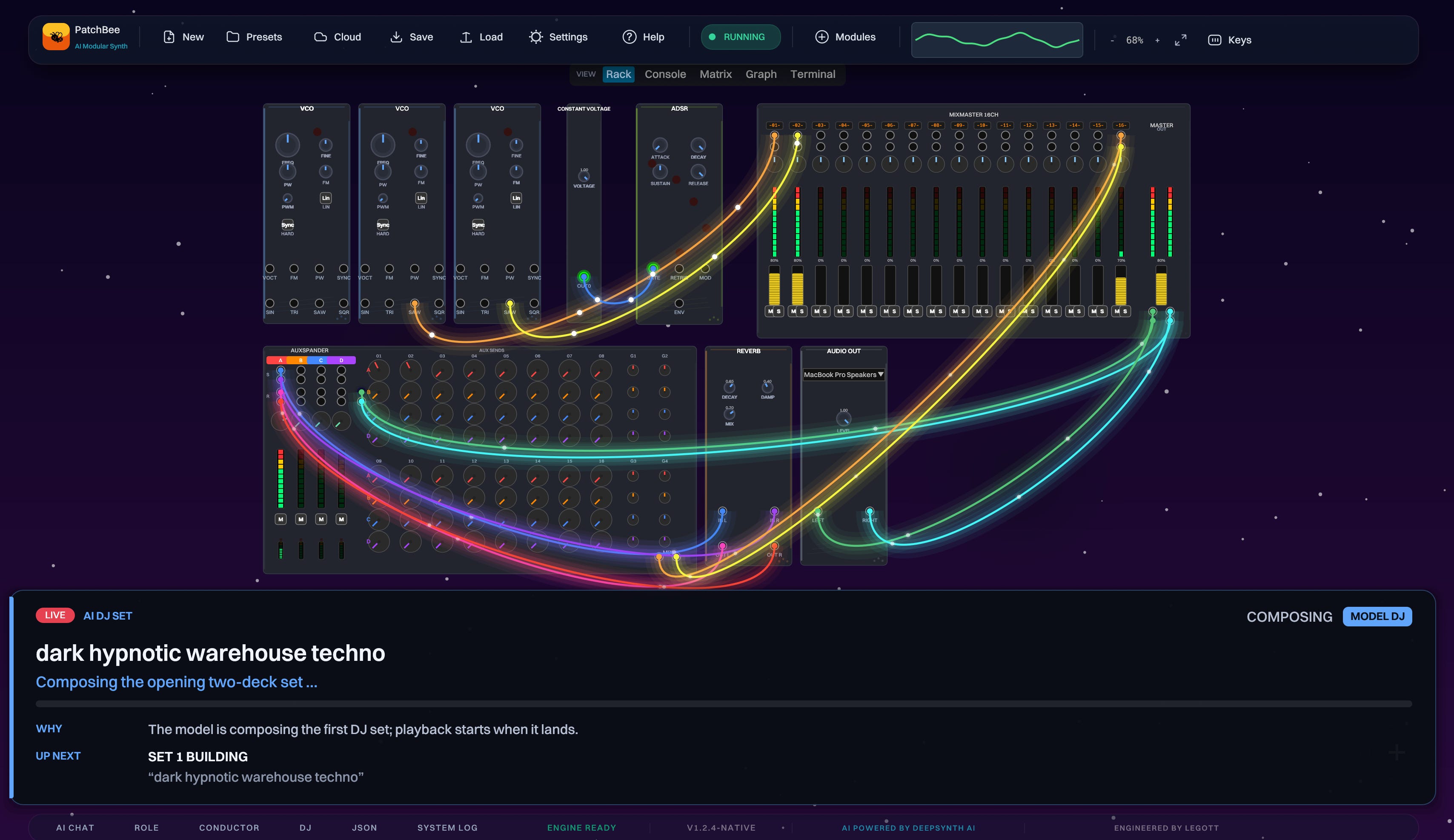
It’s extremely early — I want to go much deeper in future posts — but the architecture, briefly: small specialist models that construct the elements of a track (kick, hi-hats, bass, and so on), and a larger model I call the Conductor, which composes and coordinates the musical layers above them.
What I’m actually after
Unlimited, real-time, live patching. A model that reads the audience, reads me, and builds the EDM I’m reaching for, as it happens.
The first stage is YouTube Live. My model will patch the modular in real time — and if you’re in the chat, it will be reading you, updating and responding live. If that sounds like something you want to witness, subscribe to my channel: youtube.com/@LeGottAI. Come to the live streams. Talk to the machine.
For now, the target is techno. Not prompt-in, song-out. I mean the way a real DJ works a festival — reading the crowd, choosing the next track with intent, layering in technique, making people dance. That, but with a model at the patchbay.
Do I still want to make brilliant EDM myself and stand in front of a crowd? Of course I do. But I’m an underdog, and underdogs get one real advantage: we can afford to walk the road nobody else is walking. So that’s the road I’m taking.
Let me introduce myself one more time. I’m LeGott.
If you want to watch this world get built — patch by patch, cable by cable — subscribe to this Substack. I’ll see you at the first live.
And if you want to witness the live experiment, subscribe to the YouTube channel:
https://www.youtube.com/@LeGottAI
I’ll see you in the first room.